cs231n-lecture11图像检测和分割课程笔记
语义分割
语义分割(semantic segmentation)
输入:图像
处理:需对图片的每个像素进行分类。不区别同类目标,关注像素点。这也是它的不足。
输出:
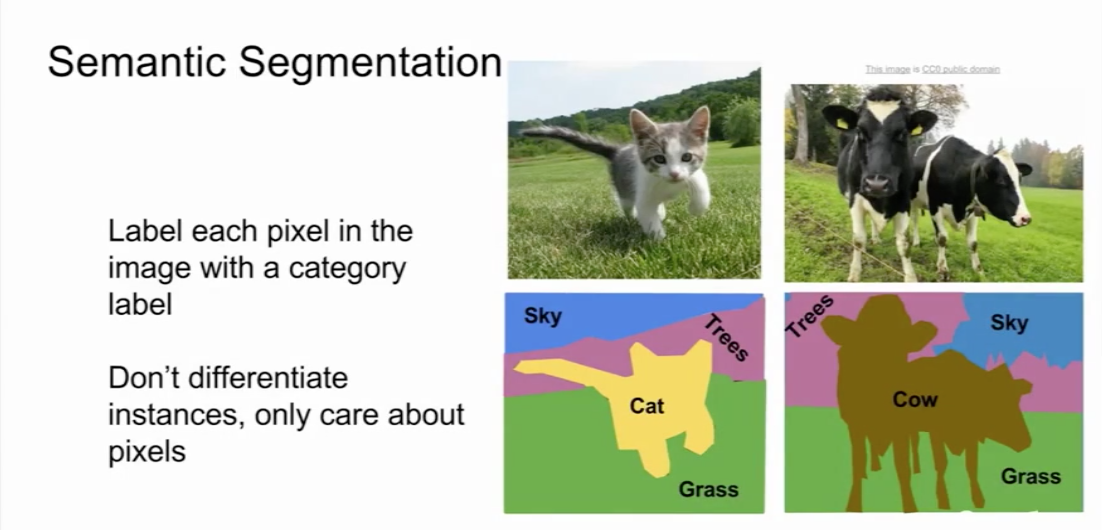
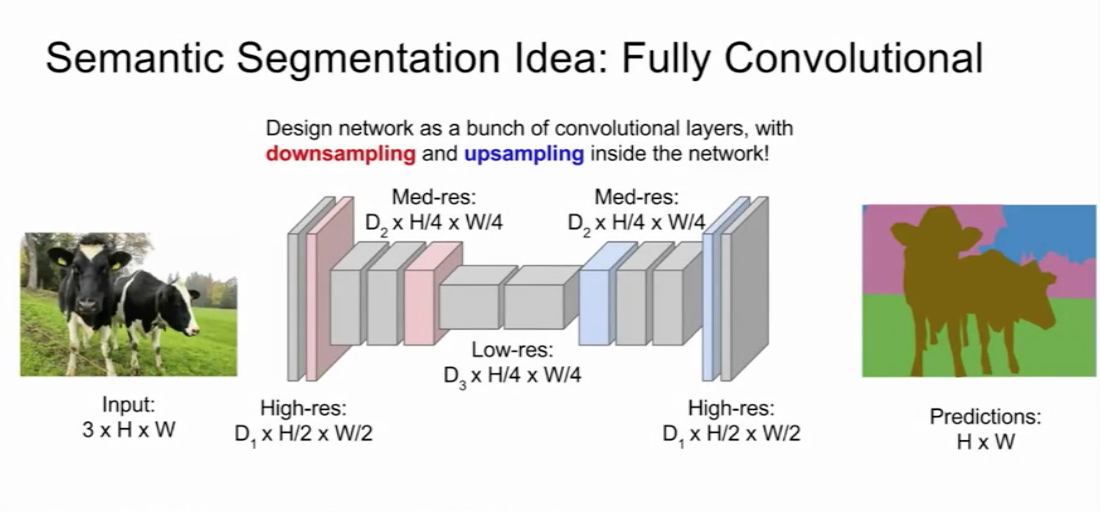
可行方法:
- 滑动窗口Sliding Window,将原始图片分成局部小块,进行图像分类,并将小图片的中心像素进行类别标记。由此循环,计算复杂度极高。因为卷积过程中有很多重复计算,两块小图片很可能一半是重叠的。
- 全连接卷积网络。
分类定位
分类和定位(Classification + Localization)
与目标检测不同,定位前提是知道某物体是要找的,或者不止一个。先对图片进行物体分类,再画上边界(bounding box)告知物体位置。
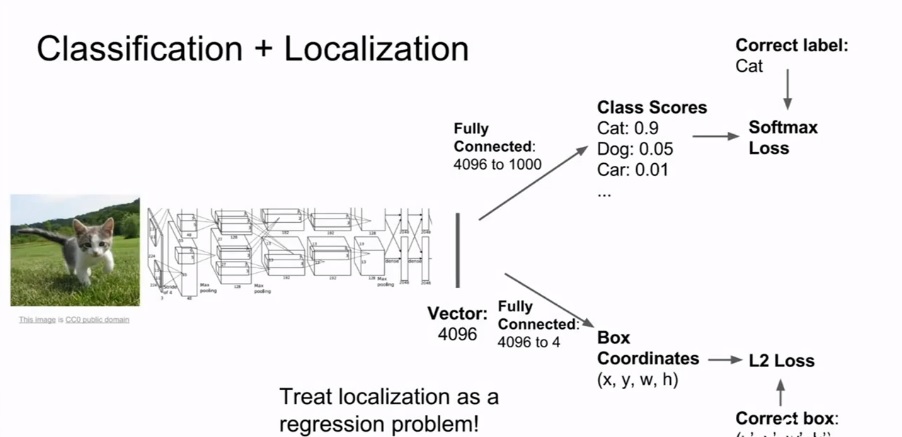
多任务loss(multi-task loss)一般处理,参数加权求和。
人体姿势估计(Human Pose Estimation)
图像中固定几个点的思路:除了分类和定位,还可以应用到人体姿势估计(Human Pose Estimation)上
输入:人像图片
输出:人体关节的点位(假定14个关节点位),网络预测人体姿势
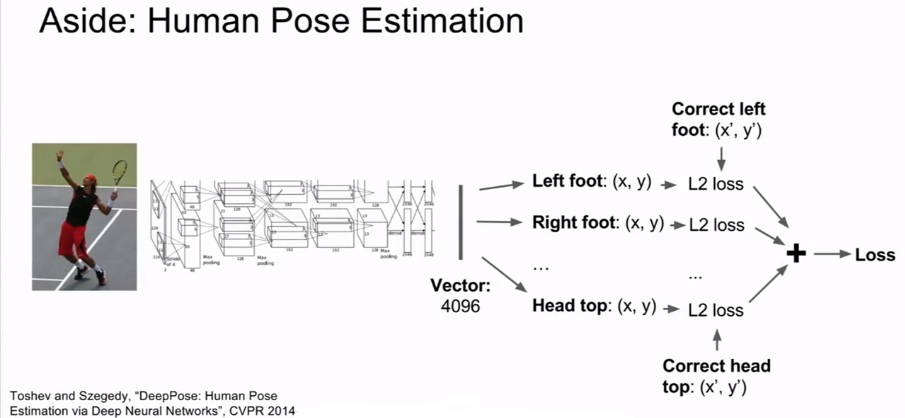
回归损失:L2欧几里得损失,(平滑)L1损失
分类问题,考虑交叉熵损失,softmax损失或SVM边界类型损失。
对象检测
对象检测(object detection),计算机视觉核心领域
输入:图像
输出:根据固定类别,每当图像中出现其中类别的对象时,围绕对象画框(box),并预测从属类别。与分类定位不同,因为每张输入图片其中的对象是不固定,所以此问题具有挑战性。
可行方法:
-
使用滑动窗口。如何选择窗口(图块)大小? 复杂度特别高
-
候选区域(region proposals)
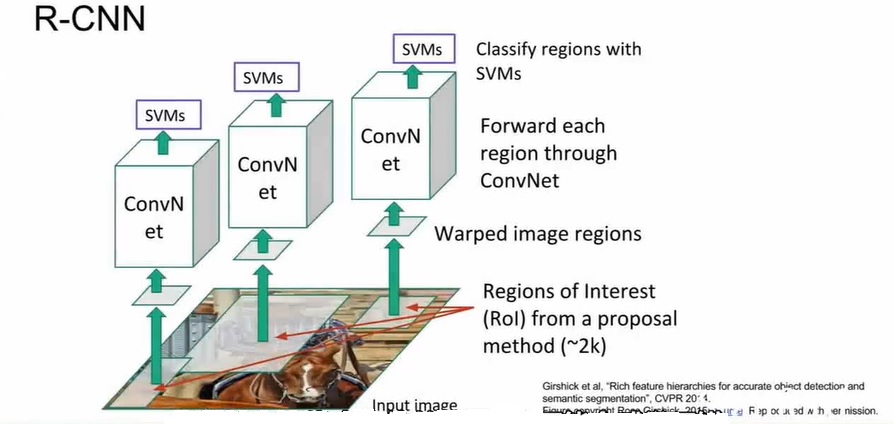
R-CNN (基于候选框的目标检测模型),使用region proposal network寻找备选区域,(也叫兴趣区域或ROI) 可以得到大概2k的ROI,但是ROI尺寸不同,为了进入CNN,调整备选区域为固定尺寸。基于区域选择的CNN(R-CNN)可以做回归,用于矫正对象外的框(bounding box),不光对这些备选区域进行分类,还对边界进行预测和调整。是多任务损失。
R-CNN问题:效率低,时间空间复杂度很高
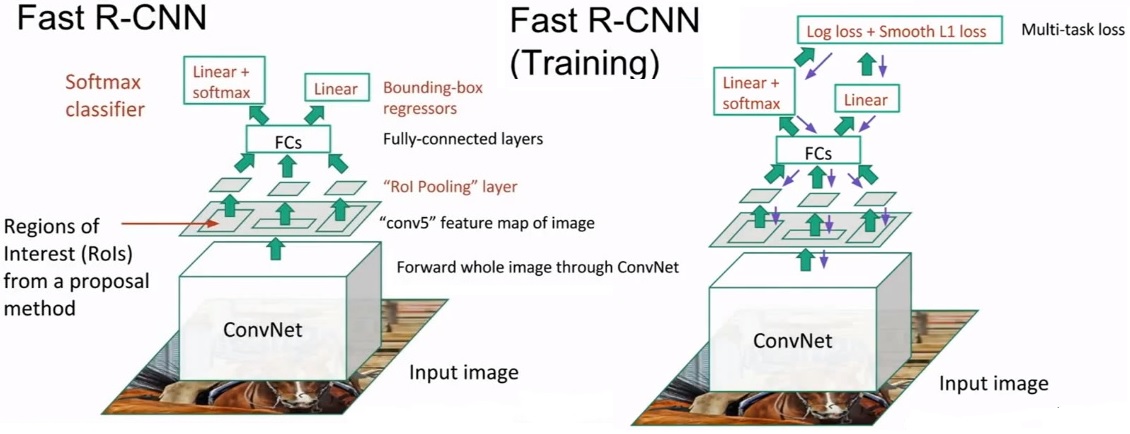
Fast R-CNN:不在按ROI处理,先通过一些卷积层网络,对于feature map再使用备选区域,Selective Search选择搜索。
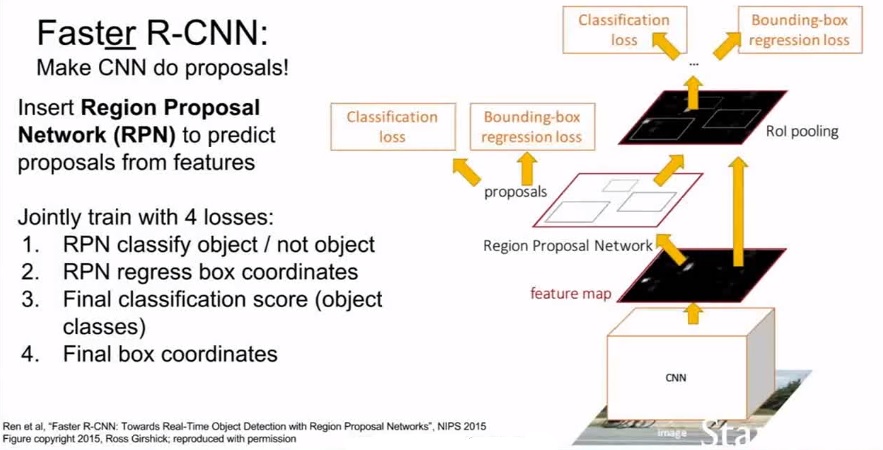
Faster R-CNN
- Detection without Proposals :YOLO/SSD
图像分割
图像分割 Instance segmentation
输入:图像
输出:类似于对象检测,还需要预测出整个分割区域。对象检测+语义分割
Mask R-CNN,效果很好